Tutorial description, case, and objectives
This tutorial will introduce how to share and contextualise annotations created in the Media Suite in a way that follows the principles of FAIR (Findability, Accessibility, Interoperability, Reusability). As a researcher, it is desirable to create annotations that can be understood, used and reused by others, enabling you to connect and enhance your research with others. The FAIR guiding principles help you with this as they emphasise “enhancing the ability of machines to automatically find and use data, in addition to supporting its reuse by individuals” (Wilkinson et al., 2016). FAIR must be seen as a way of thinking, a consensus, and does not make suggestions for specific technologies or solutions. Instead, it acts as a direction to help you evaluate your choices to make your research, data and annotations as usable as possible to others.
The FAIR guiding principles have become more and more prominent within various academic disciplines, and also within digital scholarship. FAIR is also relevant to the CLARIAH Media Suite. As Susan Aasman et al. explain in their essay on the video annotation tool of the Media Suite, “[t]he growing importance of digital research infrastructures, archives and tools, has enticed media historians to rethink their research practices more and more in terms of methodological transparency, tool criticism and reflection.” This includes the annotations you create for your research, and consistently and comprehensively organising this data to make them as availabe as possible.
Due to the way the Media Suite is organised and because of privacy reasons, it won’t be possible to automatically create and share datasets to such an extent that it can fully be called FAIR. However, it is still desirable to make your annotations as FAIR as possible, especially if you want to export your research data to another environment as it enables others to reuse and/or enhance your dataset. This tutorial focuses on the steps you need to take towards making your annotation data FAIR including options you should consider. Finally, the tutorial covers lists of repositories and thesauri that may enable you to make your dataset as FAIR as possible by following established standards used by a diverse set of research communities, including the pros and cons to help you choose the most fitting options for your particular dataset.
Objectives
This tutorial functions as a tool to assess your dataset in light of the FAIR guiding principles and to help you make annotations accordingly.
Types and levels of teaching and research
This tutorial supports sharing and contextualising annotations and research data. In general, the tutorial may be used in any field where building, annotating, and linking corpora consisting of different media items are necessary skills, such as qualitative analysis research as well as data-driven approaches to media analysis. Moreover, this tutorial is also useful for students and researchers who want to familiarise themselves with the ethics and contemporary discussions within the digital humanities concerning data management and stewardship, with the CLARIAH Media Suite as a case study.
Prerequisites
This tutorial is suited for advanced users with experience in working with the CLARIAH Media Suite’s annotation functionalities. It is recommended to be familiar with the annotation workflow before following this tutorial. If you’re not familiar with the Media Suite’s annotation functionalities, you can consult the tutorial on this topic here .
Steps: How to make your data FAIR
Introduction: What is FAIR?
As previously mentioned, FAIR stands for Findability, Accessibility, Interoperability, and Reusability. It was first introduced by Wilkinson et al. in 2016 and has since been endorsed and adopted by many data stewards, specialists, researchers, and other stakeholders. How does FAIR data stewardship influence user-generated annotations in the CLARIAH Media Suite? Within CLARIAH, the FAIR principles have been used in several research projects, such as the PLAYFAIR and Fair Photos (See https://www.clariah.nl/nl/projecten/fair-data-for-historical-games and https://zenodo.org/records/8096991.). In these projects, the focus lies on re-use and connecting datasets. Within the CLARIAH Media Suite, the FAIR principles are also applicable but the focus lies on generating FAIR (meta)data and annotations. In this part of the tutorial, we will take a look at what the FAIR guiding principles specifically mean for creating annotations. To do this, we first need to take a look at the kinds of annotations you can make, and the different possibilities within them. Throughout this tutorial, several questions will be asked to help you navigate through all the options and choose the ones that fit the specifics of your research.
Creating FAIR annotations
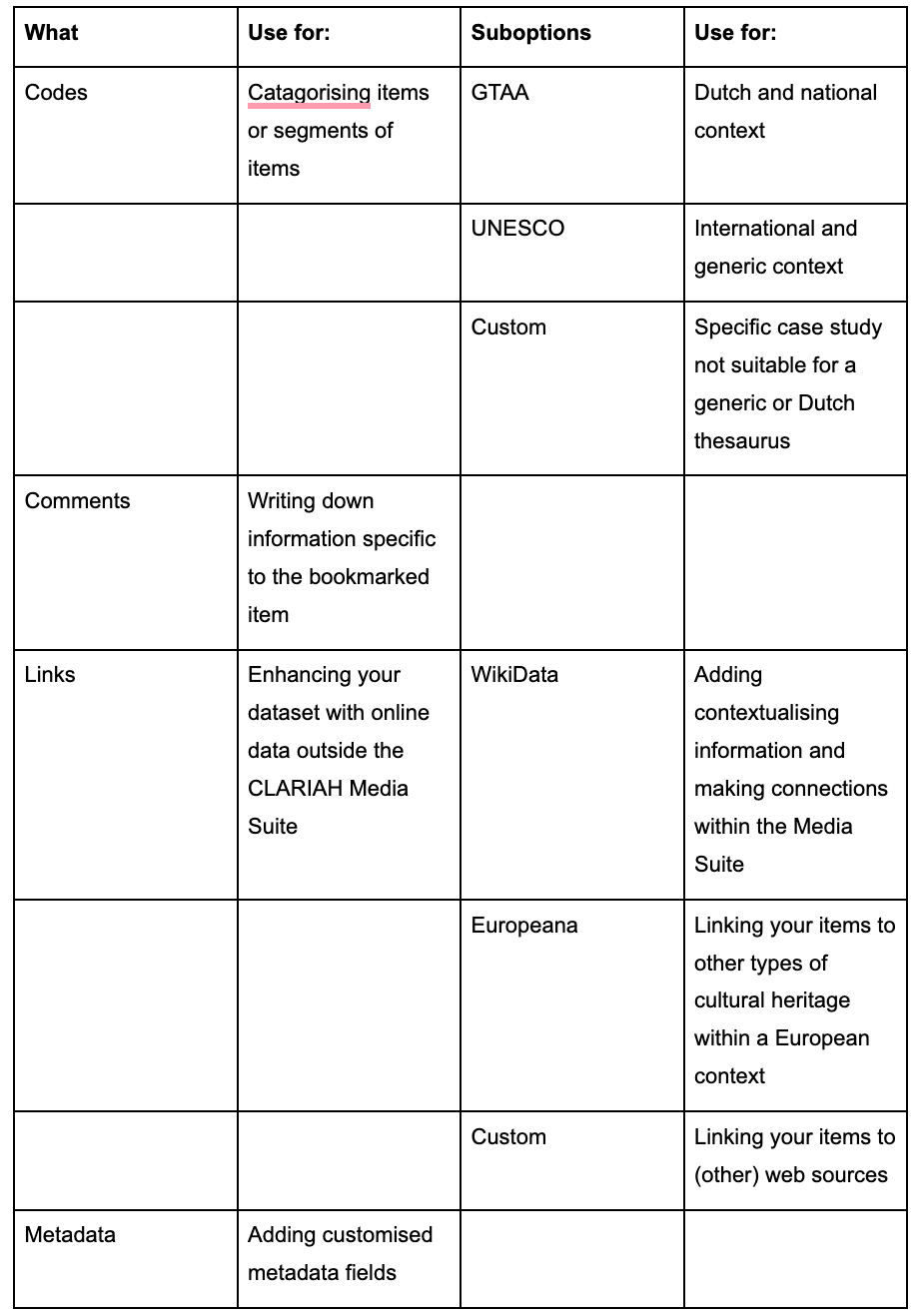
There are four kinds of annotations you can make in the Media Suite: codes, comments, links, and metadata. These kinds of annotations can be made standardised or customised. This section explains the different possibilities within these kinds of annotations. In the steps below, we walk you through how these different kinds of annotations raise questions about how to document and standardize your data.
Codes
Codes stand for “classifications from selected or custom vocabularies”, which means that you can categorise an item or segments of the item according to the specifics of your research. What is important with codes is that there is a set with agreed meanings. Within this type of annotation, you can choose between so-called vocabularies, which are two thesauri, GTAA and UNESCO, and ‘Custom’.
In the CLARIAH Media Suite, there are two thesauri you can choose from: GTAA and UNESCO . GTAA stands for Gemeenschappelijke Thesaurus voor Audiovisuele Archieven (Common Thesaurus for Audiovisual Archives) and is being used by several Dutch Archives such as NISV and Eye Filmmuseum. The UNESCO thesaurus is more suitable for interdisciplinary research not specifically tied to audiovisual material or the Netherlands. Depending on the scope and potential uses of your research, you can choose a thesaurus (or both) accordingly.
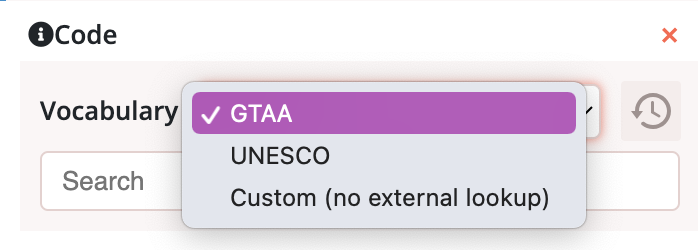
Creating annotations that make use of these thesauri has the benefit that your annotations are standardized and supported by the Media Suite, which makes your annotations more findable next to other datasets. A downside of using a thesaurus is that the terms might not fit the specifics of your research. For example, film-related terms, such as “production company” and “militant cinema”, have different meanings in other disciplines or due to their niche usage might not always be included in a thesaurus. In this case, customised codes might be a better fit in which you can use terms like these as codes.
If you choose to create customised codes, it is advisable to explicitly mention and explain your reasoning somewhere, such as in a README file. A README file is a file you attach to your dataset explaining how you organised your data and what you need to properly read and (re)use the dataset, such as prerequisites, structures, and technicalities, but also your contact information. For an example of what to include in such a README file, click here .
It is also possible to use taxonomies and controlled vocabularies that are shared by others*. You can find these for instance on Onomy (media/audiovisual specific taxonomies) and Linked Open Vocabularies (generic controlled vocabularies). On these websites, you can search for a fitting taxonomy or controlled vocabulary based on subject, discipline, or language. When creating codes, you can use these as a reference to structure your codes coherently. You can explain your reasoning behind your choices in the README file.
A taxonomy is “a collection of terms that are organized into some structure that provides some semantic understanding of those terms” ( Picturepark.com .) A controlled vocabulary is a collection of standardized or agreed-upon terms that are used to identify content.
Example questions to ask about your research:
-
Can you pragmatically use terms from an existing thesaurus to describe your case, or is this not desirable? In the case of the latter, it is better to customise your codes.
-
Does your research fit best in a Dutch context (GTAA) or is it more internationally oriented (UNESCO)? What consequences may this have for how and where you want to share your annotations at a later point?
-
Does your research fit best within an AV heritage context (GTAA) or can you make use of more generic thesauri (for example UNESCO), and what would be the potential drawbacks of the latter? Which thesauri would then be appropriate?
Comments
Comments are textual comments or notes and are a good place to write down anything that can’t be tied to a controlled vocabulary. The difference between codes and comments is the way they are being ordered within your Media Suite project. Codes are used to categorize bookmarked items and connect them to other bookmarked items whereas comments are used to write down information specific to the bookmarked item itself. Therefore, codes can be used for a more quantitative approach, such as dividing all your bookmarked films into colour or black and white film. Comments, on the other hand, can be used to write down information specific to the item itself that does not necessarily relate to the other bookmarked items. For instance, you can point out wrong titles or write down questions. Below, you can see the differences between comments and codes:

For the clarity of potential users of your annotations, it is advised to still make this section consistent in some way. For example, you can create an overview of how you have been using this comment section. Use terms that don’t have ambiguous meanings and are open to multiple interpretations. Also in the case of comments, a README file can help you specify what these comments were created for.
You can also find controlled vocabularies that might be a good fit with your research on onomy.org. Onomy is a website “where you can create and share taxonomies, folksonomies, and other forms of controlled vocabularies for use on the semantic web” (onomy.org, https://onomy.org/). Here, you can also share your customised thesaurus once you have created one so other researchers can use yours.
Example questions to ask about creating comments:
-
Which information gathered from the item or segment do you want to capture in the comment? Is the comment section the right place for this information or are there other annotation types that would work as well?
-
Are there terms you could use to write down your comments accurately? If so, what are your definitions of these terms?
Links
Links refer to external web resources, identified by URLs. They’re similar to codes in that they are a shared resource with definitions, but different in that they are not controlled vocabularies (e.g. wikidata links can disappear without warning). In the CLARIAH Media Suite, you can make use of two APIs that provide access to URLs from shared vocabularies, namely Wikidata and Europeana . It is also possible to add your own URLs under Custom if you wish to use a different vocabulary. Links to shared vocabularies enable you to create annotations with well-defined, shared terms, making it possible to link it to data outside the CLARIAH Media Suite that uses the same terms. Using shared terms helps researchers to find data(sets), link them across collections and reuse them in different contexts, supporting the FAIR principles.
Wikidata is a freely accessible knowledge base that is readable and editable for humans and machines. It is a practical way to add contextual information (for example, persons, organizations, geographical places, historical events) as annotations in a readable manner, as long as there are items about what you refer to. Wikidata is also used for the Sound and Vision Collections and to make connections with it in the Media Suite. In the tutorial on searching and exploring with linked Wikidata , it is explained how LOD can help to identify different entities with the same name and searching inside and outside the Media Suite while using it. For more information on how Wikidata works click here .

**Europeana **is an organisation that “supports the cultural heritage sector in its digital transformation” (Europeana, last accessed on March 8, 2024, https://www.europeana.eu/nl/share-your-data). On Europeana, you can find a variety of online heritage collections from European archives ranging from film to books, arts, photography, music, fashion, and archaeology. Europeana is therefore a great way to link your audiovisual materials to other types of cultural heritage within a European context.
If you want to link the item to a web source outside Europeana or Wikidata, such as a YouTube video, you can select Custom . To avoid long URLs in your annotations, you can give them an alternative name in Label .
Example questions to ask about links:
- To what kind of information do you want to link your item to? Which web source would be the best fit according to the descriptions above, WikiData, Europeana, or custom?
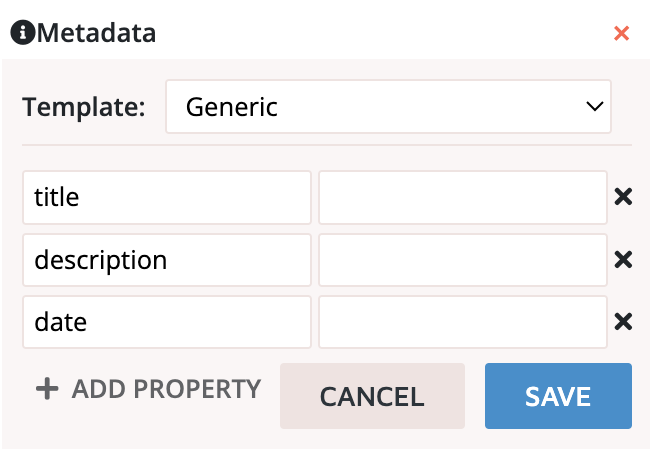
Metadata Metadata are metadata fields that you can customise yourself. As the items from the CLARIAH Media Suite contain metadata from the database in which the item is stored, this specific place is for the researcher’s own metadata. Like the comments annotations, it is advised to make this section as consistent as possible and to make clear what purpose the created metadata serve. However, it should be noted that this functionality is very labour-intensive and it is therefore advised to use this function primarily when you need to create a controlled vocabulary from scratch (see the section on Codes).
Add your FAIR dataset to a repository
Introduction: the importance of sharing and contextualising data/datasets
Now that you have documented your data in a manner that takes into account FAIR principles, you can now try to share your dataset according to these principles (see this tutorial on how to do this). Sharing and contextualising your data and datasets is an important part of FAIR; it enables your research to be found and potentially re-used. In this part of the tutorial, two repositories are highlighted that are specifically fitting for a dataset created in the CLARIAH Media Suite. These repositories are The DANS Data Station Social Sciences and Humanities and Zenodo .
**The DANS Data Station Social Sciences and Humanities **is the central institutional repository for research data in the Netherlands. Adding your dataset to this repository means that it is likely to be grouped with and connected to other datasets created with the CLARIAH Media Suite and it contributes to creating more transparency around the research practices connected to the Media Suite. As this data station is specifically made for Social Sciences and Humanities, it is most suitable for datasets that fit well within these disciplines. If you need help with depositing your data, you can check this manual .
If your research is more interdisciplinary, you might want to consider Zenodo . In Zenodo, you can either add your dataset to a ‘community’ or create your own. In case your research is more particular and/or has an interdisciplinary approach, this repository might be a better fit for you as datasets from other fields can be added to it. Another consideration for choosing this repository is the scope of your research. As Zenodo is internationally focussed, the dataset will likely be more findable by international researchers if made available via this platfom. You can find a guide on how to submit data on Zenodo here .
If you think your dataset does neither fit the DANS Data Station nor Zenodo, you can also check the data repository finder created by Utrecht University for trustworthy alternative repositories: Data Repository Finder . With the help of a few questions, this tool helps you find a repository that fits the specific needs for sharing and publishing your data.
Next to depositing your annotations into a repository, we also advise you to make a JSON file of your dataset. A JSON file is namely a great way to share your data as it is saved in a machine readable format so it can be read by different programs. Hence, you can share your data for further use that is yet unknown at the moment. You can find the tutorial on exporting JSON files here .
Sources
Wilkinson, Mark D., Michel Dumontier, Ijsbrand Jan Aalbersberg, Gabrielle Appleton, Myles Axton, Arie Baak, Niklas Blomberg, et al. “The FAIR Guiding Principles for Scientific Data Management and Stewardship.” Scientific data 3, no. 1 (2016): 160018–160018.
Overview
Feeling overwhelmed with all the options? You can find an overview of all the annotation options discussed in this tutorial here below:
Thesauri
Looking for a suitable thesaurus? Here are some thesauri you could consider for your research: