Tutorial: Searching and analysing the Sound and Vision Radio Collection using Automatic Speech Recognition
Alexander Badenoch, Utrecht University, Februari 2023
Automatic Speech Recognition (ASR) is a technique used to identify and transcribe human speech into text. Like platforms for audiovisual contents (YouTube, Netflix), the Media Suite provides a search functionality to search within ASR-transcript of television and radio. In addition to archival metadata, ASR provides a ‘textual’ access point to the spoken contents of audio or audiovisual files, which renders it comparable in many ways to full-text search of print sources such as newspapers and books.
The Media Suite currently has speech recognition for Dutch-language content, which aims for very inclusive recognition that captures the multiplicity of usage, accents, and dialects in Dutch. It also includes a number of non-Dutch terms in its vocabularies. The media suite is running ASR on: Radio 1, Radio 5, Source catalogs (items from the Radio Programma, Weken Nederlandse Radio, and Hoorspelen collections) Television (news and current affairs) and to get a sense of the completeness you can also look here , though bear in mind these statistics may not be entirely up to date. For a quick overview of ASR in the media suite, please look at the Frequently Asked Questions page here , and for additional depth and background, you can consult the in-depth discussion by the ASR expert - and CLARIAH’s Chief Technical Officer - Roeland Ordelman here (in Dutch).
This tutorial introduces you to analysing the Media Suite’s Automatic Speech Recognition data layer for radio and transmedial research, that is to say, about phenomena that travel between media. To guide you through this topic, this tutorial searches the Sound and Vision Radio Archive for material related to the long-standing television phenomenon of the Eurovision Song Context (ESC - known in Dutch as the Eurovisie Songfestival). The ESC has been the subject of a great amount of scholarship , considering its roles in such issues as national, European, and queer identities, as well as participation and fan studies, and even studies of music.
Upon completion of this tutorial, you will have learned about:
-
How ASR renders sound into transcribed text;
-
How you might use the ASR layer for ‘distant’ reading of recurring topics and language use
-
How to use the ‘compare’ tool to compare query results in the Media Suite
-
How to combine an ASR search with linked data in the Media Suite
-
How to search within the speech transcripts of a single document
-
The possibilities and limitations of ASR for exploring the collections
-
How international scholars might work with ASR to navigate the largely Dutch-language collection of the media suite
Types and levels of teaching and research
This tutorial is aimed at the level of BA students who are learning media research methods such as discourse analysis, and exploring issues such as identification, celebrity, participation and fandom. It will touch on ways of approaching research topics such as popular reception and discussion of a media phenomenon (something that has normally been done for the ESC using print sources), discourse surrounding songs and performers, or perceptions of specific competing countries.
Prerequisites
It is assumed that the user will have some knowledge of the Eurovision Song Contest, in terms of its format and range of competing countries. The necessary knowledge can be rapidly acquired from the introductory paragraphs of the ESC’s wikipedia entry . Some technical familiarity with digital searching is assumed, as well as basic familiarity with working with the Media Suite.
Acknowledgements
This tutorial was designed and refined based on two previous webinars, one for the Clariah Media Suite and for Utrecht University’s Centre for Digital Humanities. I have also borrowed some text from Emillie de Keulenaar & Liliana Melgar’s tutorial Searching and Analysing Automatic Speech Recognition (ASR) transcripts as Data Layer in Television Collections. I am grateful to Jasper Keijzer, Mary-Joy van der Deure, Jasmijn Van Gorp and Chrisian Olesen for assistance in exploring the ASR layer, careful reading and helpful suggestions.
Steps:
0: Log in, set up your workspace and create a user project
- Before you begin, you will need to get set up in the Media Suite, which involves creating a user project to work in. If you are not familiar with how to do this, you can follow the appropriate tutorial here.
1: Select collection and ASR layer
-
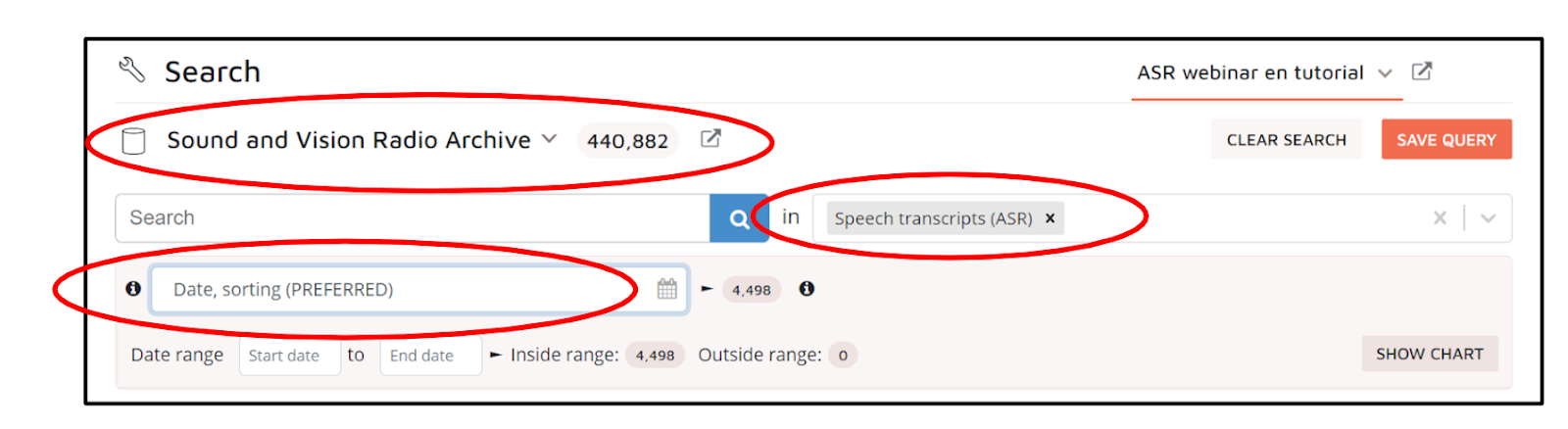
Select collection. In order to search within the Media Suite, you must first select the collection to search in. As a preliminary step, it is of course important to consider the relevance of a collection to your particular query. For broadcast content from the collections of the Netherlands Institute for Sound and Vision, the Media Suite allows you to search the radio and television collections separately or together. In this tutorial, we will be focussing on discussions about television (specifically the Eurovision Song Competition) on the radio, so we will select “Sound and Vision Radio Archive”
-
The Media Suite allows you to target your searches using different Search layers . Each search layer gives you access to different aspects of the Media Suite’s data – for example, an audio’s production date, place of airing, etc. These descriptive categories are also referred to as “metadata”. They are “meta” in the sense that they describe the contents of given data. For this tutorial, in the first instance, we will be exploring what the ASR layer looks like, so to search in ASR data only, select “Speech transcripts ASR”. Selecting this layer only is useful when your search queries are focused on what was actually said during a broadcast (for example, if you are exploring discourse on a particular subject, or trying to pinpoint moments when something was mentioned) rather than any classification that was assigned to it later.
-
In order to do ‘distant reading’ of your results over time (in this tutorial Step 3 “Analysing, comparing, and critiquing metadata results: ‘distant reading’”) you need to be able to sort your search results by date. Sorting records by date can be useful when exploring ASR date if you want to get an impression of things like language change over time. It does, however, create a challenge when dealing with audiovisual metadata, because there are often multiple dates associated with a single record - in the media suite there are 15 different date fields, not all of which are used consistently across the collection. To deal with this, the media suite has the field “Date, sorting (PREFERRED)” which automatically sorts your results by relevance, and skips empty fields. Please select this as shown in the figure below.
2. Design a basic query and refine it
-
When designing a query, it often makes sense to get a general sense of the amount of relevant material in the collection. For this tutorial, we are looking for discussion of a specific topic: the Eurovision Song Competition. The ESC has had a relatively consistent name throughout its history, though there are some variations in use, particularly between languages: in Dutch it is usually the ‘song festival’, sometimes ‘song contest’ in English, and in many languages it is simply called “Eurovision” for short (“Eurovisie” in Dutch). As such, one is most likely to arrive at all instances by using “Eurovision” as a one-word query.
-
Because ASR in the media suite is trained only to recognize Dutch (with some exceptions we will explore below), it is a good idea to use Dutch terms when searching in the media suite.. For a Dutch-language search, the more common Dutch term “Eurovisie” would be most useful as a search term. However, many specialised terms also exist in other variants, so it may also be worth trying “Eurovision”. Take a moment to try out the different variations to develop a sense of the materials’ relevance. Note that the Media Suite also allows you to search on parts of a word by using an asterisk ( * ) for the rest of the word. This can be useful when looking for different conjugations from a root word, for example. In this case, it will also allow us to search for both English “Eurovision” and Dutch “Eurovisie” at once if we use “Eurovisi*”
This basic query can give you some insights already into how often the topic appears at all in the archive, and can also serve as a comparison with a more refined query. As such is a good idea to save this query.
By way of comparison: try doing the same search only in the archival metadata layer (titles, descriptions, subject keywords, etc.) without the ASR transcripts – how big is the difference in number of records?
-
Having established that there is a baseline of records that respond to your query, it is now possible to think about how you might refine your search toward a more specific question. You might wonder, for example, how often specific countries or artists are mentioned, or whether specific terms come up in discussion. One way to approach this is by using Boolean operators. Possibilities are:
-
AND (eg “eurovisi* AND Israel”) can help you to pinpoint specific moments of discussion. Remember that it’s a good idea to use Dutch words for countries. It can help to approach this with some prior knowledge such as List of participating countries with year of debut or the list of winners by year )
-
NOT to see whether and how some terms appear eg. “Eurovisie NOT songfestival” if you are interested how often the Eurovision network is mentioned in isolation from the song contest it is most famous for; “[song title or artist] NOT Eurovisie” if you are interested in the how ESC performances might follow an artist in their career.
-
-
Another way of refining a query is to filter using the available facets which are available in the column to the left of the search results. Some might not make any sense for a query, but you can consider fields such as genre such as ‘muziekuitzending’ (music broadcast) ‘muziekuitvoering’ (music performance) and/or ‘muziekprogramma’ (music programme) or going the other way you could also look at news (nieuws) or current affairs (actualiteiten) if you were interested in when the ESC was considered ‘news’
-
If you are interested in how certain language terms are used in connection with specific people (in this case, ESC performers) it can also be effective to refine your search using linked data . (For more information on linked data in the media suite, see “Searching and Exploring With Linked Data and Wikidata in the Media Suite” ) This is another aspect of the media suite where names are extracted from metadata and assigned a role in an audiovisual program, indicating whether someone appears, performs, or is the topic of discussion. To combine these two forms of search you will need to:
-
Clear any previous search terms.
-
In the metadata field (‘in:’) menu, select ‘persons: production’, ‘persons: guests’ and/or ‘persons discussed’ - or to see where a specific person appears in any of these roles, select ‘persons all’
-
Enter the name into the search field (eg. Björn Ulvaeus; It is worth noting that linked data only recognizes people: ‘ABBA’ won’t work here) and select the name you are looking for;
-
Now, go back to the metadata menu (‘in:’) and select ‘Speech Transcripts (ASR)’;
-
Now you can couple this search to another term using a Boolean operator (AND, OR, or NOT) and another search term (eg. ‘Eurovisi*’)
-
-
Particularly if you want to compare your refined query with one or more of your base queries, save your refined queries as you go.
3. Analysing, comparing, and critiquing metadata results: ‘distant reading’
-
As we noted above, analysing the ASR layer can be very useful for investigating large patterns of use over time. You can do this by returning to one of your saved queries - it’s probably easiest to use your basic ‘Eurovisi*’ query above. Click on ‘show chart’ .
-
When you look at your results , it might be useful to consider them next to known data such as the list of participating countries or the list of winners by year that can give you some more insights into your results. Stop at this point to consider:
-
What general trends can you observe in the data?
-
Before drawing conclusions, it can be important to think about how numbers of hits in the documents relate to the total number of records for that particular year. In the media suite, you can do this by adjusting the chart visualisation from ‘absolute’ to ‘relative’. You may want to consider: (How) do your results change significantly when you slide between them? Which view seems to give you better results?
-
To further consider the quality and reliability of your query results at the distant reading stage, you can also choose to use the ‘inspect’ tool, as described in step 4 of the tutorial “Searching and Analysing Automatic Speech Recognition (ASR) transcripts as Data Layer in Television Collections” This will let you explore how many of the records you have searched actually contain ASR metadata.
-
-
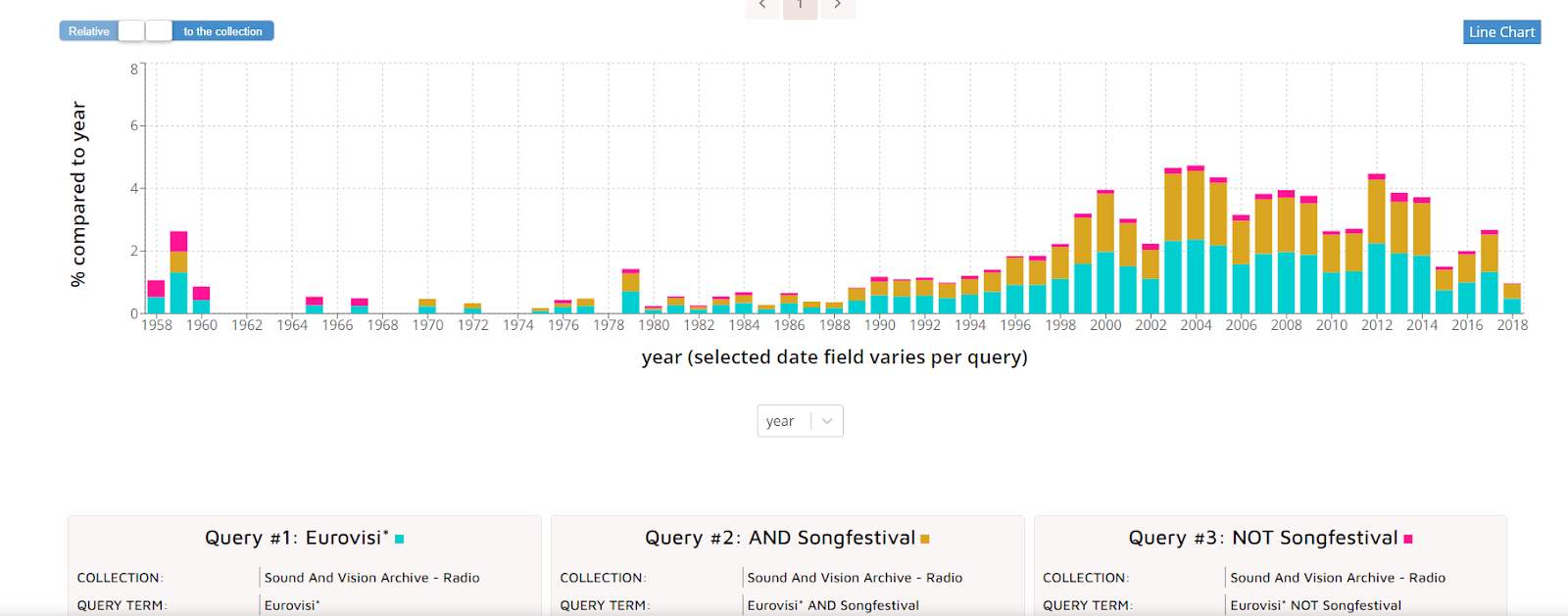
Particularly if you are trying to understand larger trends of discussions about the ESC, it may also be useful to compare your queries (see Figure below) . You might, for example, compare general appearances of the word “Eurovisie” with or without the word “songfestival” (Boolean searches using AND or NOT, respectively) if you are wondering about the extent to which one refers to the other (you can look at the chart below for the results of this). To do this, go to the ‘workspace’ menu, select ‘user projects’ and go to the project where you have saved your queries. Select two or more of your searches and select the ‘compare’ button at the bottom of the screen.
- Take a moment to reflect on the comparison. What trends or correlations do you see?
4. Filtering, examining, searching, and critiquing individual ASR records: ‘close reading’
-
As you have seen in the exercises above, searching in the ASR layer can quickly generate a corpus of potentially useful records relating to public discussions on specific topics. Besides reading this corpus ‘distantly’ for broader trends, the ASR transcripts will allow you to explore transcriptions of a number of broadcasts up close. This can serve both analytical and data-critical purposes. In this section, we will think about both.
-
Before zooming in to examine individual records, it will be useful to filter ** results manually by doing an initial scan of the list of records.** To see how this can work, type the ESC tabulation catch phrase “douze points” [twelve points] (using quotation marks to ensure that the words are used together in the search and not separately as an OR query). See the image below. You will get a short list of records, with the search terms appearing in orange bold type. It is worth noting, based on your results, that certain non-Dutch words, particularly numbers in other languages, are also within the recognized vocabularies and can sometimes be used to locate other languages. Particularly if you speak Dutch, you can quickly scan to see which of these results will be relevant to a query about Eurovision.
-
What do you notice about some of the entries?
-
If you are not a Dutch speaker, can you also see which one(s) might or might not be useful?
-
-
In a further step, we will look more closely at what you might be able to do to work with the material as a non-Dutch speaker.\

-
You can select records by using tick boxes to the left of each record, and bookmark any and all that you think will be useful to examine further.
-
Once you have a corpus of records you think are relevant, you are ready to start examining records individually. Select one record from a search on “Eurovision” that is relevant to your question or interest. Please note that it will play the segment automatically; for this exercise, you will want to stop it. If you click on the record from a fresh (as opposed to a saved) query, the audio will play out from the segment in the document where your search term appears.
-
First of all, it’s a good idea to orient around the available information . Underneath the playout bar, you will see three additional layers of information: ‘program segments’, ‘speech transcripts’, and ‘speech transcript words’ - as the names indicate, the latter two of which relate to the ASR layer. ‘Speech transcripts’ shows either blocks of light or dark - the dark ones represent blocks of time in the programme where Dutch speech has been recognized, and the light indicate little or none. ‘Speech transcript words’ presents an automatically generated word cloud of words appearing in each segment. To get a sense of how these two layers relate to the sound document, allow it to play out for a few seconds. Observe and consider:
-
What do you hear in the playout during light vs. the dark blocks?
-
How do the words in the word cloud relate to what you hear? (How) can you use this view to move meaningfully through the segment?
-

-
To access and search the full speech transcript, go to the column to the right of the playout bar and click on ‘content annotations’. From the drop-down menu ‘Type’ select ‘speech transcript’. From the drop-down menu ‘view’, make sure ‘List’ is selected. Below it, you will find the speech transcript of the whole programme. Please note that if you are working from a fresh (not saved) search query, your search term will appear in the box next to ‘list’. You can type any other search term in the box, and it will show all instances of that term in bold. When you click on a specific segment, the playout will jump to that part of the broadcast.
-
This closer view also allows you to critically examine ASR transcripts as a source for research in the collections. For Dutch speakers: scan through the whole speech transcript (you may need to delete the term from the search box).
-
How many errors can you spot?
-
How reliable does the transcription seem to you, and when is it more or less reliable?
-
What implications does this have for the conclusions you can draw from your search queries?
-
-
If you don’t speak Dutch, try selecting the segment of text in question and copying and pasting it to an online translator like Google translate or Deep L. (For more information on using Google Translate in searching the media suite, you can also look here .) Look at the results and consider:
-
To what extent are you able to make sense of the translation?
-
To what extent are you able to make use of the translation?
-
What implications does this have for the ways you could make use of the ASR layer in your research?
-
-
Well-done! You now know how to search and analyse in the NISV radio collection using the speech transcript layer, as well as how to critique results.